졸업프로젝트로 박사님이 지정해주신 논문. 너무 어려워서 이해를 못 하는 규리를 위해 간단하게 정리한다. 제가 정리한 부분에 틀린 부분이 있다면 gyurious.coding@gmail.com 으로 언제나 피드백 환영입니다. 제발 저 좀 도와주세요
우선 이 논문은 Zhou의 논문을 바탕으로 하고 있다. (자꾸 등장하는데 당최 무슨 소린지를 잘 모르겠다. )
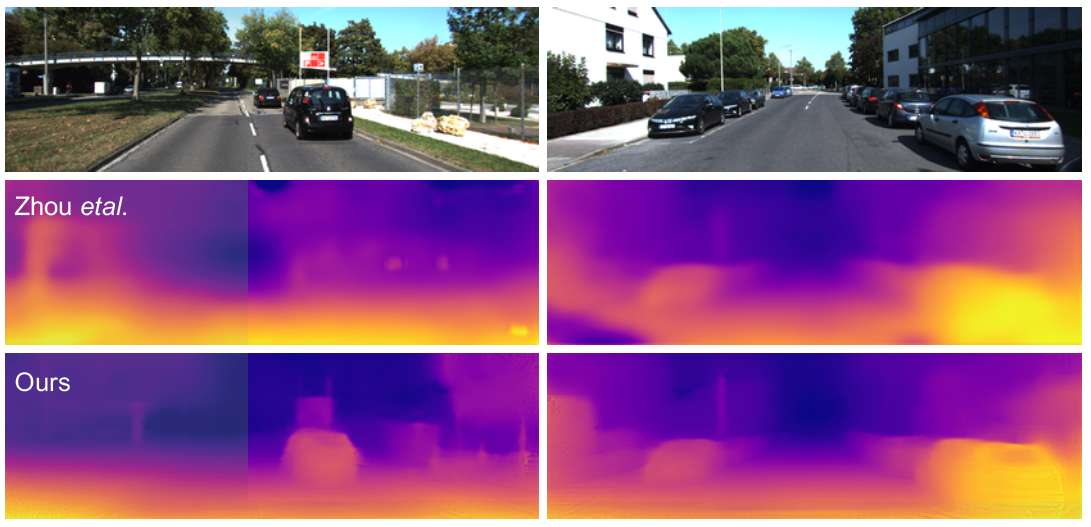
Zhou는 학습 중에 monocular video datasets에서 photometric consistency를 최소화 함으로서 poseNet과 depth CNN predictor를 분리하여 학습하는 방안을 제안했다. 뭔소리지? 하여튼 기존의 stereo video를 이용한 방안들보다는 확실하게 성취도가 떨어지긴 하지만 monocular video에서 depth estimation을 잘 해내었다는데 의의가 있는듯 하다. 작년 가을학기 때 배운 컴퓨터비전에서 stereo vision에서 depth를 추정하는 방법을 배웠었는데, monocular vision으로 어떻게 하는 건지 정말 대단하당….
monocular는 크게 다음 두가지 측면에서 stereo와 다르다.
- monocular에선 frame들 간에 camera pose를 알 수 없다.
- scale에 모호성(ambiguity)가 있다.
이런 것들을 해결하기 위해 이 논문에선 약 3가지 방법으로 애를 쓴다.
1. scale ambiguity를 해결하기 위한 simple normalization strategy
2. pose predictor에 Direct Visual Odometry(DVO)를 포함하기
솔직히 DDVO가 뭔지 아직도 잘 이해가 안 된다 ㅠㅜ
3. DDVO에 좋은 pose initialization을 제공하기 위한 pretrained Pose-CNN 사용
먼저 Image를 prepare하는데, 이 때 이미지 하나당 3개를 한 쌍으로 묶어서 training에 사용하기 때문에 data prepare를 마치면 다음 그림과 같이 3개의 image가 묶여 jpg로 저장되고, 각 image에서 카메라의 intrinsic 좌표?? 가 txt파일로 저장이 된다.

241.674463,0.,204.168010,0.,246.284868,59.000832,0.,0.,1. (cam의 intrinsic 좌표)
이 걸 왜 이렇게 세 개씩 묶어서 저장할까? 이는 이미지를 순서대로 I1, I2, I3이라고 할 때 각 이미지들의 relative pose를 계산해내 서로 warp시킨다음 비교하기 위해서이다. 이게 뭔소린지 전혀 감이 안 잡힐 수 있으니 천천히 파이프라인을 살펴보자.
전체적인 파이프라인은 다음과 같다.

귀찮으니까 차근차근 시간날 때 해야지...ㅜ
+ 그리고 졸업을 해버렸다고 한다,,,
'CS > etc.' 카테고리의 다른 글
| Conventional Commits (5) | 2020.04.21 |
|---|---|
| HTML 꿀팁 (3) | 2019.08.29 |
| RNN을 이용한 SRCNN 만들기 (3) | 2019.06.04 |


